Anthropic just 5x'd Claude Code's context to 1M. For my workflow, that's closer to 10x usable context. Let me explain. I run automated software engineering sprints with custom slash commands and...
My Thoughts
And just like the game continues to change. Where just weeks ago you wanted to preserve the context window, and avoid loading too much (with skills etc)... Now we have 5x context window.I was only running into compaction sometimes before, and never more than 2-3 times on one task. So now it would be never.I think there is still a place for skills, but arguably this changes things, some of the more important skills should now probably just be permanent context?Looking forward to seeing how this works in practice. It might be a good test to make a copy of a project and just put all the skills straight into the claude.md and compare results for the same feature build... I might just do that.

Anthropic just 5x'd Claude Code's context to 1M. For my workflow, that's closer to 10x usable context. Let me explain. I run automated software engineering sprints with custom slash commands and domain-expert subagents. By the time /implement-task kicks off, roughly 40% of the old 200k window was already consumed. System prompt, tool definitions, CLAUDE md, memory files, planning docs, expert research notes. All before a single line of implementation. Then there's the compaction buffer. Claude Code reserves a fixed 33k tokens regardless of window size. On 200k, that's 16.5% gone. On 1M, that same 33k is just 3.3%. Old window: 167k after buffer, minus 80k overhead = 87k for actual work. 1M window: 967k after buffer, minus 80k overhead = 887k for actual work. 87k to 887k. From a "5x" window increase. The fixed costs (overhead and compaction buffer) eat nearly 57% of a 200k window but only 11% of a 1M one. Then there's compaction itself. On 200k, it was inevitable for any serious task. The agent summarises your conversation, drops history, continues from a lossy summary. Context from earlier in the session just vanishes. I've been running /spec-task, /plan-task, and /implement-task sequentially on 1M and haven't broken 60%. | 10 comments on LinkedIn…
You might also like
 blog
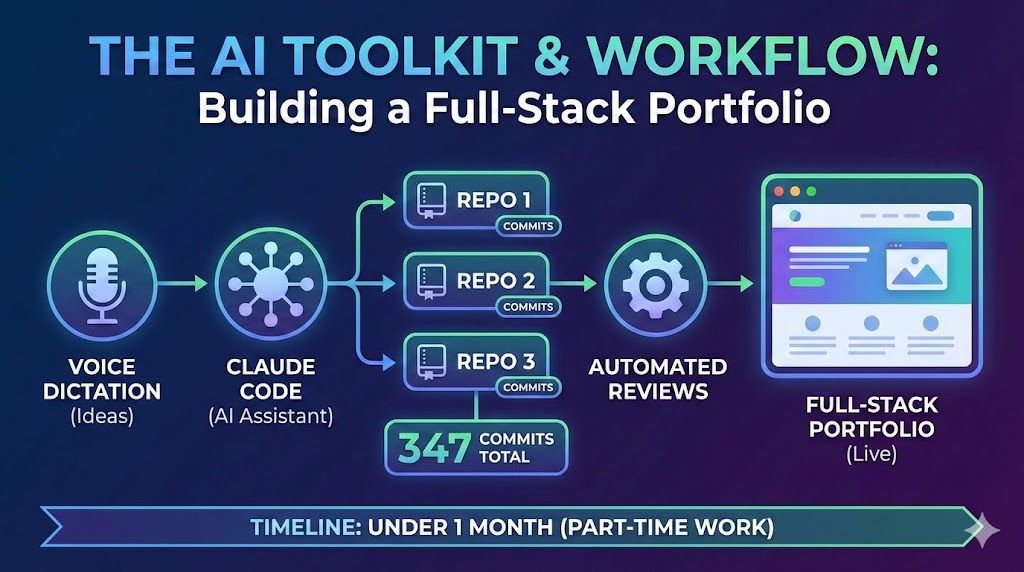
blog A Developer's AI Workflow: From Voice Dictation to Automated Reviews
The AI toolkit and workflow behind building three repositories, 347 commits, and a full-stack portfolio in under a month of part-time work — Claude Code, voice dictation, automated reviews, and more.
 blog
blog Building an efficient Content Pipeline with Claude Code: From PRs to Blog Drafts
I built a system that scans my GitHub PRs weekly, identifies content-worthy work, and generates blog drafts automatically. I call the pattern Quasi-Claw. I built a system to solve a problem most developers share: doing interesting work every week but never writing about it. The pattern — slash commands + LaunchAgents + CLI execution — turns Claude Code into a lightweight scheduled agent without any heavy framework or infrastructure. Here is how it works: 📅 The Trigger: Every Friday at 5pm, a macOS LaunchAgent triggers Claude Code. 🔍 The Scan: It scans my GitHub repos and scores PRs/commits for "content potential." 💬 The Summary: It sends me a Slack digest of the week's best stories. 🚀 The Execution: I run a single command to pick an idea, generate a full blog draft from the actual source code, and push it to my site’s API. The meta proof it works? This very post was identified and drafted by the system itself. #ClaudeCode #AI #BuildInPublic #Automation #SoftwareEngineering
 blog
blog Building an AI Portfolio Agent with Laravel, pgvector, and Gemini
A chatbot that knows everything I've written — built with the Laravel AI SDK, pgvector embeddings, hybrid search, and Gemini's free tier.